[Data Structure] Hash Table (해시 테이블)
1. 해시 테이블 (Hash table) 이란
- [키(Key)와 값(Value)] 이 하나의 쌍을 이루는 추상 자료형(Abstract data type)* 이다.
- 이 Key와 Value를 Mapping 시키는 과정을 해싱(Hashing)이라고 부른다.
- 빠른 탐색과 삽입, 삭제 속도를 가져 항목간의 관계를 모형화 하는 데에 유용하게 쓰이는 자료구조 중 하나이다.
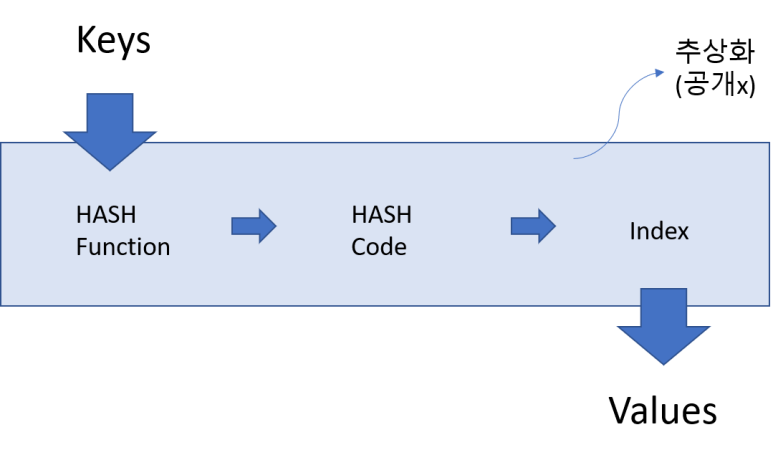
추상 자료형(ADT - Abstract Data Type) 이란?
- 인터페이스와 기능 구현 부분을 분리한 자료형.
- 기능 구현부분을 명시하지 않아(추상화 하여) 사용 시에는 기능이 어떻게 돌아가는 지 몰라도 되는 편리함이 있다.
- 대표적으로 스택, 큐, 연결리스트, 딕셔너리가 있다.
- 정확한 이해를 위해선 추상화 된 Black box가 어떻게 구현이 되었는지 직접 해보는 것이 좋다.
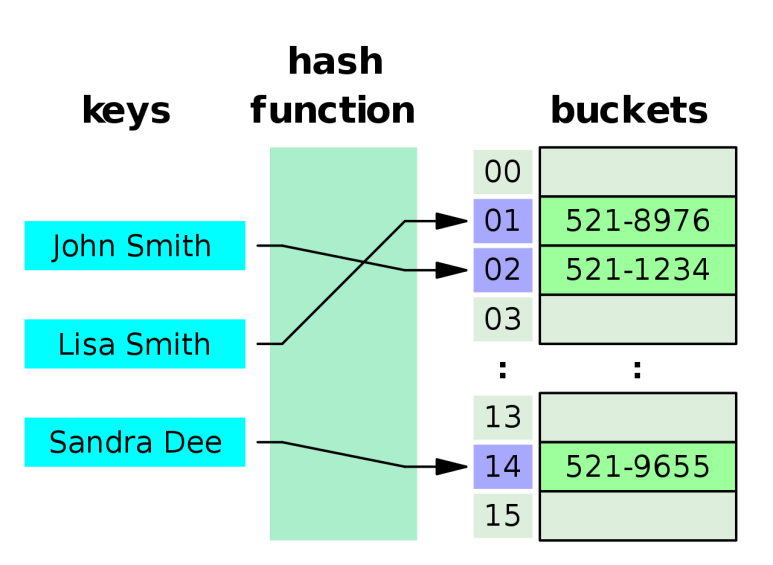 출처: 위키백과
출처: 위키백과
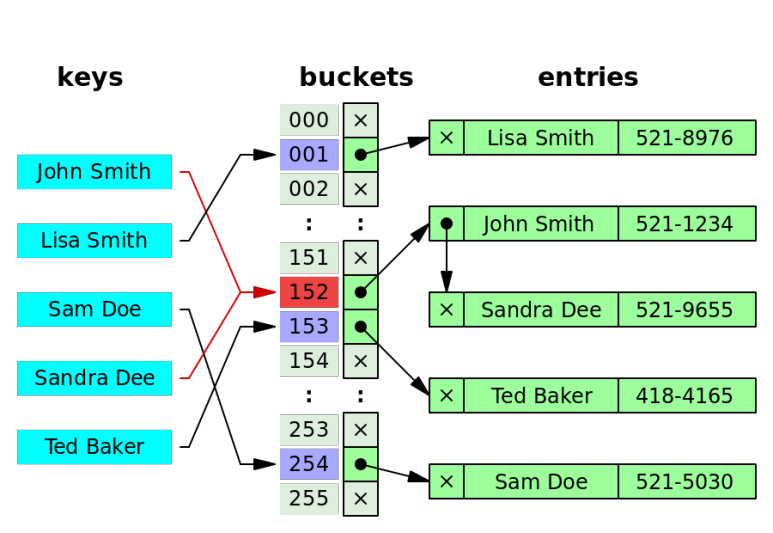
만약에 이 전화번호부가 배열에 알파벳 순서로 되어있다면 이진탐색을 써서 Lisa Smith 씨의 번호를 찾을 수 있을 것이고, O(log n)이라는 시간이 걸린다. 하지만 이름과 전화번호부를 외우고 있는 놈이 있다면 찾을 필요도 없이 이름만 대면 O(1)의 시간으로 바로 찾을 수 있을 것이다. 그놈이 해시 테이블이다.
다시 말하면, 데이터 식별자(Index)가 숫자로 이루어져 데이터를 저장 하는 배열(Array)과 List(리스트)와는 달리 해시 테이블은 인터페이스만을 보았을 때에는 데이터 식별자(Key)로 숫자 뿐만 아니라 문자열, 파일 등을 받아와 Value를 연상해 낸다고 볼 수 있다.
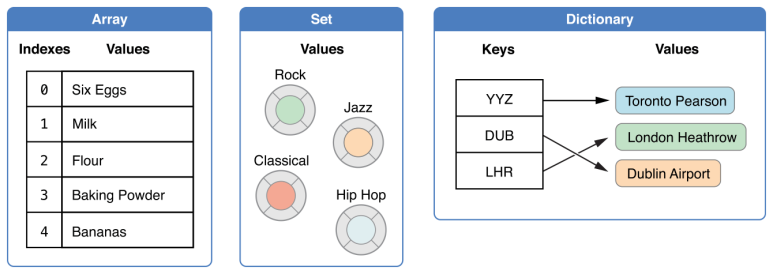
2. Same thing, different names
처음에 이 자료구조를 공부할 때 다양한 이름으로 불려서 다소 혼동이 있었다.
연관 배열(Associative Array), 맵(Map), 사전(Dicitonary) 등으로도 불리기도 한다.
물론 Map과 Dictionary 사이에는 아주 미세한 차이가 있다고는 하나 처음에는 무시해도 될 정도이다.

근래에는 이처럼 대부분 언어에서 라이브러리로 이 자료구조를 지원하기 때문에 굳이 직접 구현할 필요는 없다.
Dictionary (Python)
Hash - (Ruby, Perl)
Map - (Java, Go, Haskell 등)
Unordered_map, Map - (C++)
하지만..! 앞에서 말했듯이 이를 본질적으로 이해하기 위해선 직접 구현할 필요가 있다. 그리 복잡하지는 않으니 꼭 한번 구현해보자. (뒤에서..ㅋㅋ) 구현할 때에는 리스트와 배열로 구현한다. 구현해야 하는 이유는 여기 Link에서 포프킴씨께서 잘 설명해주신다.
3. 왜 해시 테이블이 요긴하게 사용되나?
-
평균적으로 탐색, 삽입, 삭제에 O(1)의 시간복잡도를 보인다.★★★★★
-
어떤 항목과 다른 항목의 관계를 모형화하는 데 좋다.
-
중복을 잡아내는 데에 뛰어난 성능을 보인다.
-
웹 서버 등에서 데이터 캐싱(Data Caching)을 하는 데에 사용된다.
-
해싱을 이용해 블록체인 암호화에도 사용된다.
Advantages:
1) Simple to implement.
2) Hash table never fills up, we can always add more elements to chain.
3) Less sensitive to the hash function or load factors.
4) It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
4. 단점은?
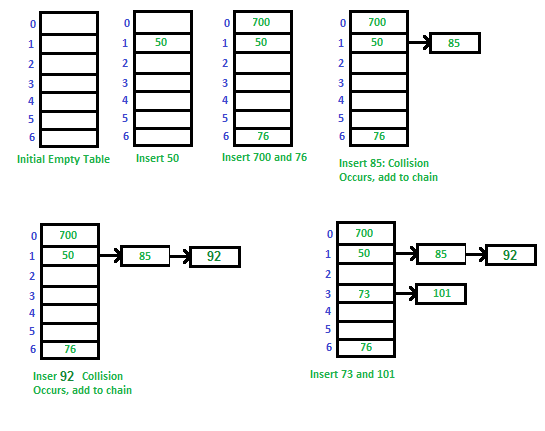
충돌 (Collision)!!
-
different keys, same code / different codes, same index
-
충돌을 줄여주는 좋.은. 해시 함수(Hash Function)을 이용하여 효율을 극대화 하여 구현해야 한다. (힘듦ㅠ) Chaining, Open Addressing 등을 이용해 collision을 극복하는 방법이 있다.
-
사용률이 0.7보다 커지면 해시 테이블을 리사이징(Resizing)해주어야 한다.
-
Chaining을 하다보면 한 곳에 집중되는 경향이 있는데, 균형잡힌(Balanced) 해시 함수를 구현해야 해시 테이블의 진정한 의미를 살릴 수 있다. 그렇지 않으면, O(1)이 아닌 O(n)의 굴레에서 벗어나지 못한다.
-
Sorting과 Ordering이 힘들다.

Disadvantages:
1) Cache performance of chaining is not good as keys are stored using linked list. Open addressing provides better cache performance as everything is stored in same table.
2) Wastage of Space (Some Parts of hash table are never used)
3) If the chain becomes long, then search time can become O(n) in worst case.
4) Uses extra space for links.
5. 좋은 Hash function 이란?
그렇다면 좋은 Hash Function의 조건은 어떠할까?
-
Use only the data being hashed
-
Use all of the data being hashed
-
Be determinstic
-
Uniformly distributed data
-
Generate very different hash codes for very similar data
※ C++ program for hashing with chaining
6. 해시 테이블 구현
이상 해시 테이블 자료구조에 대해서 알아보았다. 그럼 이제 Python을 이용하여 구현해보자.
구현 체크리스트
- 해시함수의 효율성 : 얼마나 잘 으깨주냐
-
비슷한 key에도 독립적으로 으깨지는지 (i.g. France, Francd)
-
테이블에 골고루 분배해주는지 (balanced distribution)
- 충돌방지 chaining algorithm 적용
- linked list 이용해 chaining
Python Code
class HashTable:
N = int(input("The length of Hash table"))
hash_table = [[] for _ in range(N)]
def hashing_func(self, key): # Hash function
total = 0
for i in range(len(key)):
total += ord(key[i]) * (7 ** (i + 1))
return len(key) * total
# 좋.은. 해시함수를 만들기 위한 작업
# i번째 문자를 unicode로 변환 후 7(소수)의 (i+1)제곱한 것을 다 더해줌
# key의 길이를 곱해준 후 return
def insert(self, key, value): # Hash Table 삽입
hash_code = self.hashing_func(key) % len(self.hash_table)
bucket = self.hash_table[hash_code]
key_exists = 0
for i, kv in enumerate(bucket):
k, v = kv
if key == k:
key_exists = 1
if value != bucket[i][1]: # same key, different value
key_exists = 2
break
if key_exists == 1:
bucket[i] = ((key, value))
elif key_exists == 0:
bucket.append((key, value))
else:
print("*** 중복 error : same key:", key,
", different values:", value, bucket[i][1], "***")
def search_by_key(self, key): # Hash table 검색
hash_code = self.hashing_func(key) % len(self.hash_table)
bucket = self.hash_table[hash_code]
for i, kv in enumerate(bucket):
k, v = kv
if key == k:
return v
def delete(self, key): # Hash table 삭제
hash_code = self.hashing_func(key) % len(self.hash_table)
bucket = self.hash_table[hash_code]
# print("Hash CODE : ", hash_code)
key_exists = False
for i, kv in enumerate(bucket):
k, v = kv
if key == k:
key_exists = True
break
if key_exists:
del bucket[i]
print('Key {} deleted'.format(key))
else:
print('Key {} not found'.format(key))
7. Reference
-
https://www.geeksforgeeks.org/hashing-set-2-separate-chaining/
-
해시-해시테이블-해싱 5분만에 이해하기 - Gunny 여기까지 정리를 하기 위해 아래 영상을 시청해보자. 초보자 입장에서 간결하게 설명을 잘 해준다. (5분) (YouTube에 사실 영어로된 영상도 어마무시하게 많다.)
-
[자료구조 알고리즘]해쉬테이블(Hash Table)에 대해 알아보고 구현하기 이분도 정말 기가 막히게 설명해주시는데 목소리가 너무 아름다우시다. 목소리 감상하다 시간갔던 ㅋㅋ (6분 30초)
Leave a comment