[DL] AI 직군 입사시험, AI 대학원 시험 및 면접 준비 (1)
인공지능 (AI) 테스트 및 면접 준비 (1) : 딥러닝
AI 직군 입사시험이 주말에 예정되어 있어, 나올만한 내용 포스팅해보려 한다.
[1] AI, ML, DL 차이점 설명

Figure 1 AI, ML and DL
(출처 : ML Interview QnA)
Artificial inteligence (AI)인공지능
- 인간의 지능을 인공적으로 모방, 모델링한 컴퓨터 시스템이다.
Machine learning (ML)기계학습
- AI의 한 분야로, 경험 (training data)을 통해 패턴을 자동적으로 학습하는 시스템을 말한다.
Deep learning (DL)딥러닝
- ML의 하위 개념으로, 많은 경험(큰 사이즈의 dataset)을 인간 뇌 기능의 다층 구조를 모방한 인공 신경망 구조로 학습하는 시스템을 말한다.
- DL은 ML이기도 하지만 dataset의 크기가 클 때 유용하다.
- Neural Nets (NN)의 목적은 어떤 함수 $f$를 fitting하는 것이다. 즉, $y=f(x;\theta)$를 정의하고, 입력 값 $x$를 토대로 출력 값 $y$를 추정하는 것. 모델이 최적의 함수에 근사하도록 NN의 parameter $\theta$를 학습하는 것이다.
[2] ML 에서의 학습 방법 설명
Supervised learning지도학습
- Target이 존재한다. 즉, 컴퓨터가 label레이블, 라벨이 있는 training dataset을 이용하여 학습한다.
- Continuous target variable: regression회귀 문제에 활용 (linear regression선형회귀, 현재 내가 하고 있는 speech separation task 등)
- Categorical target variable: classification분류 문제에 활용 (logistic regression로지스틱 회귀, Naive Bayes, KNN, SVM, decision tree 등)
Unsupervised learning비지도학습
- Target이 존재하지 않는다. 즉, 컴퓨터가 label이 없는 training dataset을 이용하여 어떠한 특정 가이드라인 없이 학습한다.
- 컴퓨터가 데이터로부터 패턴 및 관계를 clustering군집화해서 자동적으로 추론한다.
- K-means와 같이 clustering 문제를 푸는 데에 활용 되기도 하고, principal component analysis (PCA)주성분 분석 등의 차원 축소, t-distributed stochastic neighbor embedding (t-SNE) 등의 시각화 방법으로도 사용된다.
Reinforcement Learning강화학습
- 컴퓨터가 trial and error시행착오를 거쳐 최적화 된 패턴 또는 방법을 학습한다.
- 강화학습으로 학습하는 시스템을 ‘agent’라고 부르는데, 주어진 환경에서 action을 취하고, 그 action에 대한 error나 reward를 반영한다.
- Agent는 이러한 trial and error를 통해 최대의 reward를 가져다 주는 action을 찾아내야 한다.
[3] MLP로 XOR 논리를 표현하려면 최소 몇 개의 hidden layer가 필요할까?
- 0개의 hidden layer은닉층 (a.k.a. logistic regression, single layer perceptron) 모델로는 XOR 출력을 표현할 수 없다.
- Actication function활성화 함수인 Sigmoid는 단조 증가함수이므로, Sigmoid에 대한 입력이 증가한다면, $Z$ 값도 증가하게 되어 “linearly separable”한 decision boundary를 생성하다.
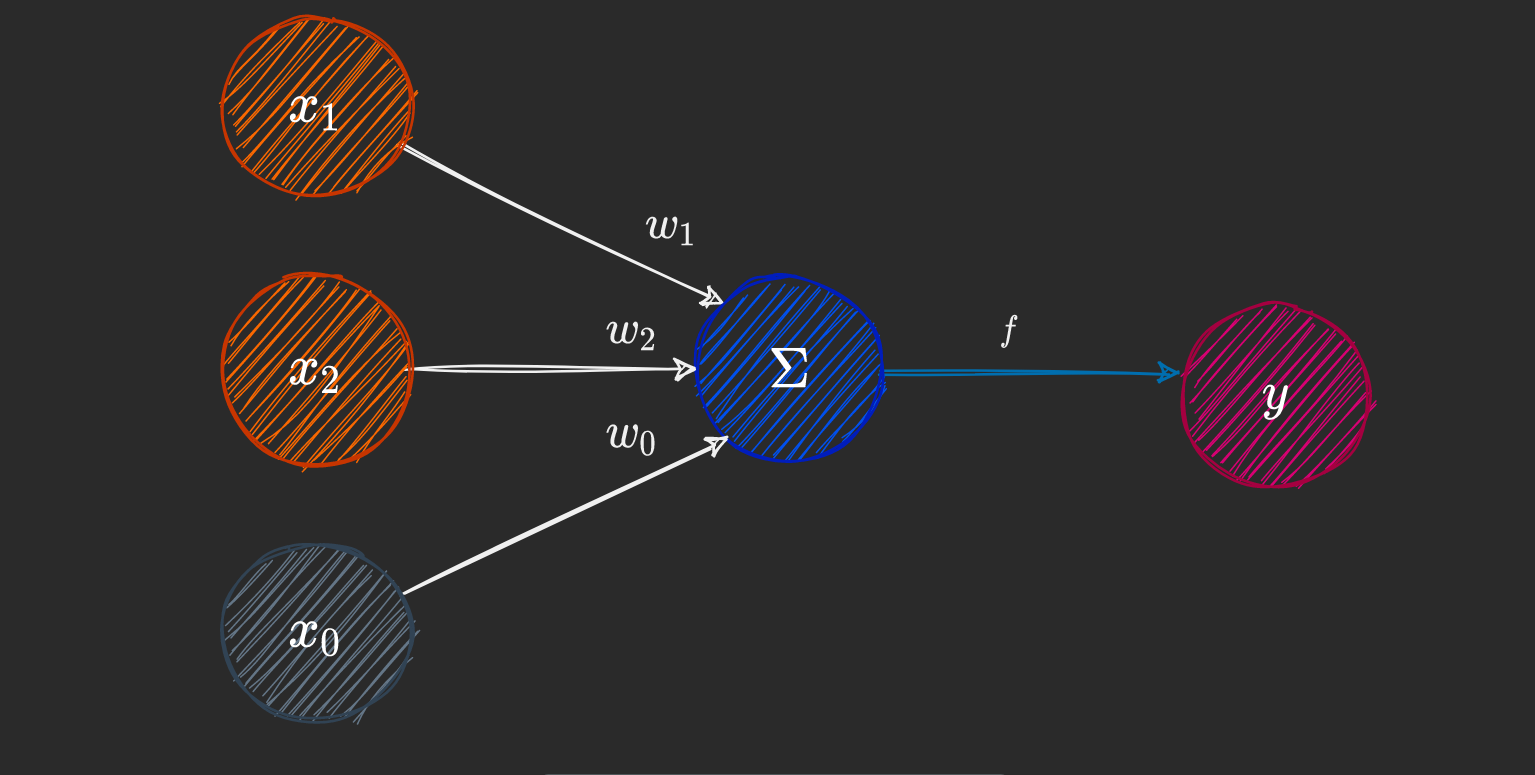
Figure 2 A representation of a single-layer perceptron with 2 input nodes
(출처 : How Neural Networks Solve the XOR Problem)
- 하지만, XOR 문제는 아래 Figure 3에서 보이는 것과 같이 linearly separable선형 분리하지 않기 때문에 perceptron 하나로 정의할 수 없다.

Figure 3 A potential non-linear decision boundary for our XOR model
(출처 : How Neural Networks Solve the XOR Problem)
-
답을 먼저 말하면, 시벤코 정리에 의해 최소한 1개 이상의 hidden layer를 가진 multi-layered perceptron (MLP)이 XOR 문제를 풀 수 있다.
-
Hidden layer에서 non-linearity비선형 변환을 통해 XOR 문제를 풀 수 있다.
- Hidden layer의 노드는 single-layered perceptron과 크게 다르지 않다.
- 이전 레이어의 output들을 input으로 받아 weight, bias와 가중합 계산이 되고, activation function 통과하여 output 값이 나오게 된다.
- 이때 핵심은 MLP의 activation function으로 non-linear을 사용하는 것이다. 자세한 설명은 다음 섹션에서..
[4] Why non-linear activation function?
- 우리가 실전에서 직면하는 문제 중에는 위의 XOR 문제처럼 선형으로 분리되지 않는 문제가 많이 있다.
- 따라서 이럴 때는 딥러닝처럼 non-linear transformation으로 데이터의 분포에 매핑하는 것이 강력한 학습, fitting 능력을 발휘할 때가 있다.
- 그렇다면, 어떠한 activation function을 써야할까?
- Backpropagation역전파로 parameter를 업데이트 하기 위해서 differentiable미분 가능한 function이어야 한다. (사실 이 제약은 무시해도 된다. 뒤에 ReLU function에서 설명)
- Non-linear function이어야 한다. Linear function을 사용한다면, 아무리 깊게 레이어를 쌓아도 결국 하나의 linear layer가 되어버리기 때문이다.
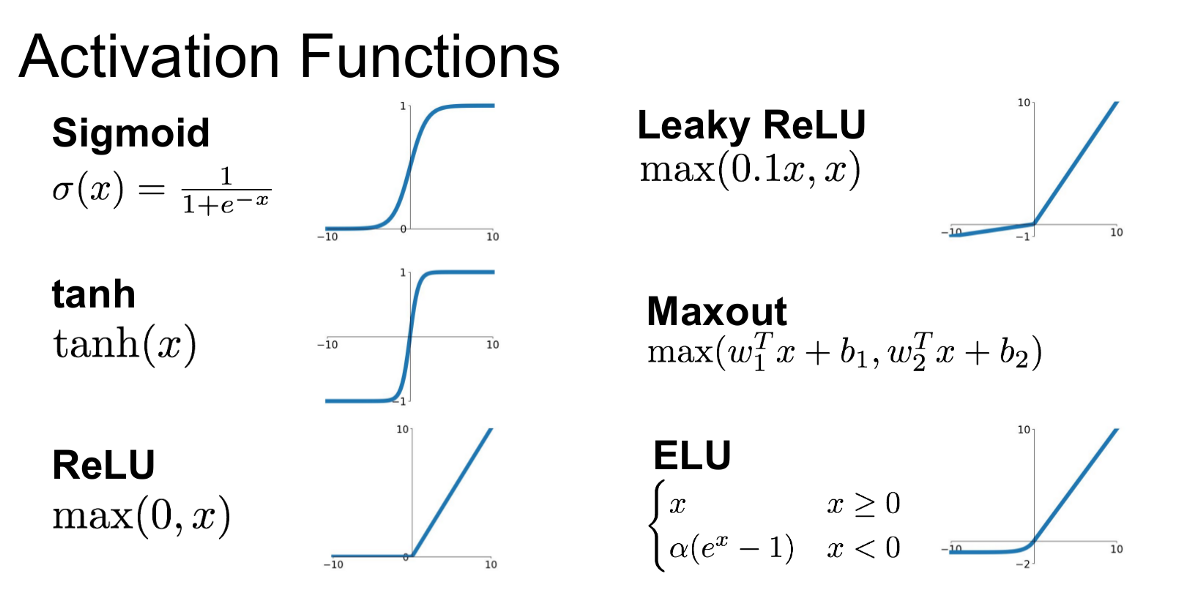
Figure 4 Different Activation Functions and their Graphs
(출처 : Introduction to Different Activation Functions for Deep Learning)
[5] 자주 사용하는 activation function과 도함수
1. Sigmoid function
\[\sigma(z)=\frac{1}{1+e^{-z}}\] \[\sigma'(z)=\sigma(z)(1-\sigma(z))\]HOW TO?
- 합성함수의 미분법 $h(x)=f(g(x)),\ h’(x)=f’(g(x))f’(x)$
2. Hyperbolic Tangent (tanh) function
\[f(z)=tanh(z)=\frac{e^{z}-e^{-z}}{e^z+e^{-z}}\] \[f'(z) = 1-(f(z))^2\]3. Rectified Linear Unit (ReLU) function
\[f(z) = \text{max}(0,z)\] \[f'(z) = \begin{cases} 1, & z>0 \\ 0, & z\le0 \end{cases}\]What?? ReLU는 $z=0$ 에서 미분 불가능하잖아?
- Gradient based optimization 알고리즘에서 backpropagation을 하려면 미분 가능해야 하기 때문에, ReLU는 deep learning에서 activation function으로 적합한 함수가 아닌 것처럼 보인다.
- 하지만, 실제 NN 학습 과정의 구현체에는 이런 상황에서 도함수가 정의 될 수가 없다고 에러를 띄우지 않고 주로 한쪽 방향에서의 미분 값을 return하도록 구현되어 있다.
- 만약 $g(0)$의 값을 나타내도록 요청 받으면, 정확히 $0$ 값으로 나타내지 않고 $0$ 근처의 아주 작은 값으로 나타내도록 구현되어 있다.
- 다시 말해, hidden layer의 activation function의 non-differentiability는 practical한 관점에서 무시해도 괜찮고, ReLU를 이용한 gradient descent는 여전히 잘 작동하고 널리 쓰이고 있다.
[6] 왜 Sigmoid와 Tanh는 gradient vanishing 현상을 일으킬까?
Sigmoid 함수와 Tanh 함수는 다음 Figure 5과 같다.

Figure 5 Sigmoid and Tanh
(출처 : Stackexchange)
Sigmoid
- Sigmoid 함수는 입력 $z$를 구간 (0, 1)로 매핑시킨다. 이 때문에 logistic function이라고도 불린다.
- 입력 $z$가 큰 수일 때에는 $f(z)$는 1에 가까운 값을 갖게 되고, 반면에 작은 수일 때에는 0에 가까운 수를 갖게 된다.
- Sigmoid를 미분하면 $f’(z)=f(z)(1-f(z))$인데, 위처럼 $z$ 값이 아주 크거나 아주 작아지면 $f’(z)$ 값이 0에 가까워지기saturated때문에 gradient vanishing기울기 소실 현상이 발생한다.
Tanh
- Tanh 함수는 Sigmoid 함수를 평행이동 및 상수배를 한 함수나 마찬가지이다.
- 따라서, 입력 $z$ 값이 클 때에는 $f(z)$가 1로 수렴을, 작을 때에는 -1로 수렴한다.
- 또한 Tanh 함수도 Sigmoid 함수처럼 미분 값도 입력 $z$ 값이 매우 크거나 매우 작을 때 모두 0으로 수렴하기 때문에, gradient vanishing 현상이 발생한다.
[7] Activation function으로서 ReLU 계열 함수의 장점 및 한계점
장점
- Sigmoid와 Tanh 함수보다 계산 복잡도가 평균적으로 낮고, 하나의 임계치만 있으면 활성화 값을 얻을 수 있다.
- ReLU 함수는 non-saturation비포화 성질로 인해 gradient vanishing 문제를 해결할 수 있고, 상대적으로 넓은 활성화 경계를 제공하여 모델이 더 빠르게 학습하고, 더 좋은 성능을 내도록 할 수 있다.
- 단측면 억제로 인해 NN의 sparse representation희소 표현 능력을 제공한다.
This means that negative inputs can output true zero values allowing the activation of hidden layers in neural networks to contain one or more true zero values. This is called a sparse representation and is a desirable property in representational learning as it can accelerate learning and simplify the model.
한계점
Dying ReLU problem
- Training 과정에서 (-) gradient가 ReLU를 통과하면, 0이 되어버려 뉴런 노드가 죽는 문제가 발생하여 이후에 어떤 데이터가 들어와도 활성화 되지 않는다.
- 따라서, ReLU로 인해 죽은 뉴런 노드를 지나는 gradient는 영원히 0이 되어서 다른 데이터에 영향을 미치지 않는다.
- 대다수의 뉴런 노드가 죽으면, backpropagation으로 gradient를 업데이트 할 수 없어 training에 실패할 수 있다. 최악의 경우에는 모든 뉴런 노드가 죽어 상수함수가 되어버리는 경우가 있겠다.
- Dying ReLU problem을 유발하는 원인으로는 큰 learning rate과 큰 negative bias가 있는데, ReLU를 통과하기 전 $z$의 값을 음수로 만들기 쉬운 요소들이다.
개선 방안

Figure 6 Different ReLU functions
(출처 : NYU deep learning course)
Leaky ReLU
\[f(z) = \begin{cases} z, & z>0 \\ az, & z\le0 \end{cases}\]- ReLU function의 변종으로, $z<0$일 때 값이 0이 되지 않고 기울기가 $a$인 선형 함수로 구성된다.
- 이 때, $a$는 아주 작은 normal number이고, ReLU와 마찬가지로 단측면 억제를 구현하는 동시에 (-) gradient 정보를 버리지 않고 부분적으로 유지한다.
Parametric ReLU (PReLU)
- Leaky ReLU에서는 경험적으로 적당한 $a$ 값을 찾아야 하는 단점이 있다.
- 이러한 단점을 보완한 것이 PReLU인데, 바로 $a$를 학습가능한 parameter로 설정하여 backpropagation으로 네트워크와 함께 최적화 시켜준다.
Random ReLU (RReLU)
- Leaky ReLU에서 $a$를 어떠한 분포에서 random sample한 값으로 설정하는 함수이다.
- 일정 정도 정규화 작용을 한다.
Leave a comment