[DL] AI 직군 입사시험, AI 대학원 시험 및 면접 준비 (3)
인공지능 (AI) 시험 및 면접 준비 (3)
[15] RNN의 gradient vanishing/exploding 문제 원인과 해결 방법
BPTT Back Propagation Through Time 시간오차역전파
RNN Recurrent Neural Networks 순환신경망 계열 모델은 long-term dependency장거리 의존 관계를 잡아내기 위해 BPTT 알고리즘을 사용한다. 사실 BPTT는 단순히 RNN 계열의 sequence model을 time series와 같이 앞 뒤 순서가 존재하는 sequential data에 응용하기 위해 backpropagation training 알고리즘을 변형한 것이다. BPTT는 sequence의 처음부터 끝까지 error를 backpropagation하기 위해 모든 input timestep을 펼친 neural network 형태에서 작동한다고 생각할 수 있다. 즉, 각 timestep은 하나의 input과 output, 그리고 network의 복사본으로 구성되어 있다. Error가 각 timestep 마다 계산되고 누적되고, 다시 접혀진 상태에서 hidden weight들이 업데이트 된다.
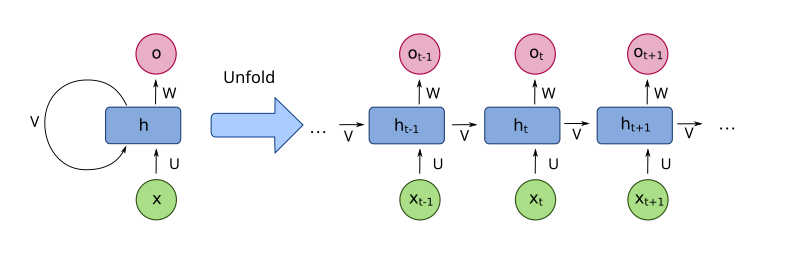
Figure 1 Unfolded RNNs
(출처 : Wikimedia Commons)
Gradient vanishing/exploding 문제
BPTT의 의도는 long-term dependency를 잡아내는 것이었지만, 실제 vanilla RNN 모델에서 BPTT를 이용한 방법은 gradient vanishing 때문에 성공적이지 못하였다.
그 이유는 predicted error가 신경망의 각 층을 따라 backpropagation되는데, Jacobian matrix야코비안 행렬의 최대 eigenvalue고윳값가 1보다 작을 때, gradient의 크기는 지수적으로 줄어들기 때문에 gradient vanishing 현상이 나타난다. 즉, 출력층에 가까운 몇 개의 가까운 층만 학습 작용을 하게 되어 long-term dependency 관계를 학습하기 어렵게 한다.
반면에, Jacobian matrix의 최대 eigenvalue가 1보다 크고 출력과 거리가 멀면 멀수록 각 층의 gradient 크기가 지수적으로 늘어나 gradient exploding을 야기한다.
Gradient vanishing 문제 해결
이 문제는 모델 자체에 대한 개선이 필요한데, gradient exploding 문제보다 해결하기 까다롭다.
- RNN hidden state에 여러가지 gate를 추가한 LSTMLong-Short Term Memory GRUGated Recurrent Unit 모델을 사용하는 것
- The identity RNN architecture : Activation function으로 ReLU(Rectified Linear Unit) function을 사용하며, 모든 recurrent weight들이 1로 초기화 된 RNN 모델을 사용
Gradient exploding 문제 해결
Gradient exploding 문제는 gradient vanishing 문제보다 간단하게 해결할 수 있다.
- Gradient clipping 방법 : Gradient의 norm (보통 L2 norm을 사용)이 사용자가 지정한 특정 값을 초과하면, gradient에 대해 등비축소하는 방법으로 문제를 풀 수 있다. 이 방법은 gradient vector의 방향은 유지하고 크기만 안정적으로 모델이 학습을 할 수 있도록 줄여주는 방법이다.
Leave a comment