[DL] AI 직군 입사시험, AI 대학원 시험 및 면접 준비 (2)
인공지능 (AI) 시험 및 면접 준비 (2)
[8] Overfitting과적합과 Underfitting과소적합
Overfitting

Figure 1 A good example of overfitting
- Overfitting이란 말 그대로 모델이 training dataset에 과하게 fitting되는 현상이다.
- 일반적으로, 평가 지표를 보았을 때 training set에 대한 성능은 매우 좋은데, test set이나 새로운 데이터 상에서 성능이 좋지 않다.
- 모델이 데이터의 특징을 지나치게 학습하여 노이즈 데이터의 특징도 학습하게 되고, generalization되지 않는다.
Underfitting
Underfitting은 모델이 training이나 inference 과정에서 모두 좋은 성능을 보이지 못할 때를 말한다. 모델이 데이터의 특징을 잘 잡아내지 못하는 경우이다.
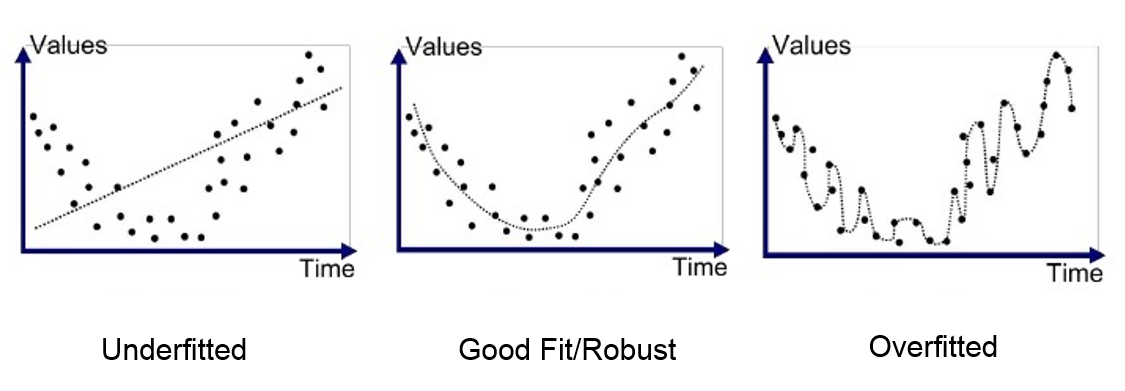
Figure 2 Overfitting and underfitting
(출처 : What is underfitting and overfitting in machine learning and how to deal with it.)
[9] Overfitting과 그 위험을 낮출 수 있는 방법은 무엇이 있을까?
(1) More data
데이터 샘플이 많을수록 모델은 일반화된 유효한 특징을 학습하는 동시에 노이즈에 대한 영향을 줄일 수 있다.
Data Augmentation데이터 증강
- 이미지의 경우 회전, 수축, 확장, 평행이동 등의 방법으로 데이터 증강을 할 수 있다.
- Generative model생성모델을 활용하여 대량의 신규 데이터를 추가하는 방법도 있다.
- 요즘엔 self-supervised learning 방법으로 label이 없는 데이터를 가지고도 supervised learning - unsupervised learning을 hybrid 관점으로 접근하는 방법이 있다.
(2) Lower model complexity모델 복잡도 낮추기
- 데이터가 비교적 적고, 모델이 지나치게 복잡하면 overfitting을 유발할 가능성이 높다.
- 모델의 복잡도를 낮추면 모델이 노이즈 데이터에 overfitting되는 것을 막을 수 있다.
- NN에서는 layer나 parameter 수를 줄이는 방법이 있겠다.
(3) Regularization정규화
- Loss function에 weight term을 추가하여 weight이 비이상적으로 커져 과적합 되는 것을 방지한다.
- 즉, 전체적으로 weight의 크기를 작아지게 하여 학습 과정에서 local noise에 영향이 적게 가도록 한다.
- L2 regularization 또는 weight decay라고도 한다.
(4) Ensemble앙상블
Ensemble은 학습 과정에서 다숭의 모델을 합쳐 단일 모델에서 올 수 있는 overfitting 위험을 낮춰준다.
(5) Dropout드롭아웃
- Dropout은 training 시 일정한 비율로 일부 뉴런 노드를 임시적으로 버리는 것을 뜻한다.
- Training dataset의 각 batch에 적용되는데, 뉴런 노드가 매번 random하게 버려질 때마다 서로 다른 구조의 NN에서 training하는 것과 같은 효과를 얻어 딥러닝 모델에서의 ensemble 알고리즘 이라고 볼 수 있다.
- Mini-batch 급에서 작동하기 때문에 수많은 NN의 training과 평가를 할 수 있다.
- 매 training 마다 임의로 선택된 서로 다른 뉴런 노드 집합을 동시에 최적화 하기 때문에 전체 뉴런의 co-adapting을 약화시키고 overfitting 위험을 줄여 일반화 성능을 향상시킨다.
[10] Weight Initialization초기화
What if 모든 parameter 동일하게 초기화?
- FCNN의 경우, 모든 뉴런 노드가 동일한 input과 output을 가지게 되어 foward propagation과 backpropagation의 값이 모두 같게 될 것이다.
- Training 과정에서 이러한 대칭성을 깨주지 못하면 최종 NN의 parameter는 여전히 동일할 것이다.
Why important?
- The initial point can determine whether the algorithm converges at all, with some initial points being so unstable that the algorithm encounters numerical difficulties and fails altogether.
- The aim of weight initialization is to prevent layer activation outputs from exploding or vanishing during the course of a forward pass through a deep neural network.
- If either occurs, loss gradients will either be too large or too small to flow backwards beneficially, and the network will take longer to converge, if it is even able to do so at all.
Random Initialization (LeCun Init.)
- 이러한 대칭성을 깨주기 위해 random하게 parameter를 초기화 한다.
Xavier Initialization
- 이전 노드와 다음 노드를 고려하여 초기화 한다.
- ReLU함수에서 사용 시 출력 값이 0으로 수렴하게 되는 현상이 나타난다.
-
He Initialization
- Xavier init.에서 ReLU를 activation function으로 사용 시 비효율적인 결과를 보이는 것을 개선한 것이다.
[11] 왜 sparse representation?
Model sparsity희소성
- 모델의 많은 parameter가 0이 되는 상황
- Feature selection을 하여 비교적 중요한 feature만을 남겨둔 것
- 모델의 generalization 성능이 높아지고, overfitting 위험을 낮출 수 있음
[12] Convolutional Neural Networks (CNN)합성곱 신경망
Sparse interaction희소 상호작용
- FCNN은 입-출력 뉴런 사이에 모두 상호작용이 발생한다.
Parameter sharing파라미터 공유
Transition equivariant이동 등변 성질
[13] 여러가지 pooling 방법들
Pooling의 목적?
- To represent the previous layer’s output in a compact form without noise
Mean pooling
Max pooling
[14] ResNet
- NN을 깊게 쌓으면 gradient vanishing이나 exploding 문제가 발생한다.
- Skip connection으로 이전 layer의 출력을 다음 layer에도 그대로 전달한다.
- Gradient vanishing이나 exploding을 막아 모델 구조가 깊어져도 training error가 낮다.
Leave a comment